The big data analytics market is growing fast, driven by the rapid increase in volume and complexity of enterprise data in virtually every industry. Leading among analytics engines and frameworks, Apache Spark features greater speed and scalability compared to many competitors.
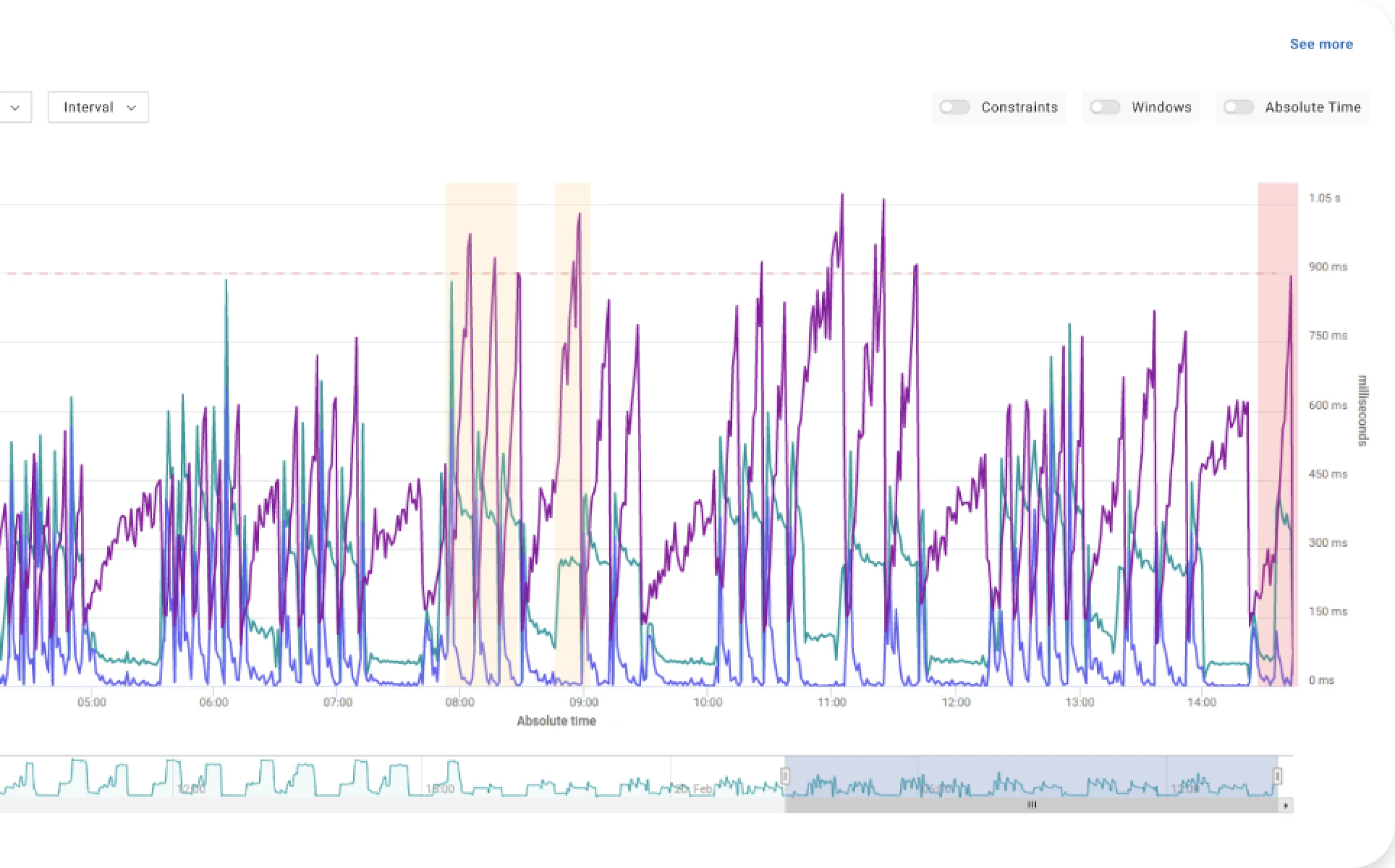
The power and flexibility of Spark make it a notoriously complex tool to tune, with highly sensitive configurations to the kind of application. Given the high level of parallelism usually associated with Spark jobs, misconfigured applications can waste a significant amount of resources and cluster time, inflating the infrastructure costs of operating your big data solutions.
These are only some of the results that we achieved with autonomous performance optimization:
- Decrease memory footprint by 50%;
- Reduce 20% of execution time;
- Save 80% in optimization effort and time.